Find out how to Learn Deepseek
페이지 정보

본문
 Tencent Holdings Ltd.’s Yuanbao AI chatbot handed DeepSeek to change into essentially the most downloaded iPhone app in China this week, highlighting the intensifying domestic competition. I’m now working on a model of the app utilizing Flutter to see if I can point a cellular model at a neighborhood Ollama API URL to have similar chats while deciding on from the identical loaded fashions. In different words, the LLM learns tips on how to trick the reward mannequin into maximizing rewards whereas lowering downstream performance. DeepSeek AI, a Chinese AI startup, has introduced the launch of the DeepSeek LLM family, a set of open-source large language fashions (LLMs) that achieve exceptional ends in numerous language tasks. But we shouldn't hand the Chinese Communist Party technological advantages when we don't have to. Chinese corporations are holding their very own weight. Alibaba Group Holding Ltd. For instance, R1 makes use of an algorithm that DeepSeek previously launched referred to as Group Relative Policy Optimization, which is much less computationally intensive than other commonly used algorithms. These strategies have allowed firms to take care of momentum in AI improvement despite the constraints, highlighting the constraints of the US policy.
Tencent Holdings Ltd.’s Yuanbao AI chatbot handed DeepSeek to change into essentially the most downloaded iPhone app in China this week, highlighting the intensifying domestic competition. I’m now working on a model of the app utilizing Flutter to see if I can point a cellular model at a neighborhood Ollama API URL to have similar chats while deciding on from the identical loaded fashions. In different words, the LLM learns tips on how to trick the reward mannequin into maximizing rewards whereas lowering downstream performance. DeepSeek AI, a Chinese AI startup, has introduced the launch of the DeepSeek LLM family, a set of open-source large language fashions (LLMs) that achieve exceptional ends in numerous language tasks. But we shouldn't hand the Chinese Communist Party technological advantages when we don't have to. Chinese corporations are holding their very own weight. Alibaba Group Holding Ltd. For instance, R1 makes use of an algorithm that DeepSeek previously launched referred to as Group Relative Policy Optimization, which is much less computationally intensive than other commonly used algorithms. These strategies have allowed firms to take care of momentum in AI improvement despite the constraints, highlighting the constraints of the US policy.
 Local Deepseek Online chat online is attention-grabbing in that the different variations have different bases. Elixir/Phoenix might do it also, though that forces an online app for an area API; didn’t seem practical. Tencent’s app integrates its in-house Hunyuan artificial intelligence tech alongside DeepSeek’s R1 reasoning model and has taken over at a time of acute curiosity and competition around AI within the country. However, the scaling regulation described in earlier literature presents varying conclusions, which casts a dark cloud over scaling LLMs. However, if what DeepSeek has achieved is true, they may quickly lose their advantage. This improvement is primarily attributed to enhanced accuracy in STEM-associated questions, the place significant good points are achieved via massive-scale reinforcement studying. While current reasoning fashions have limitations, this can be a promising analysis course as a result of it has demonstrated that reinforcement learning (with out people) can produce models that study independently. This is rather like how humans discover ways to exploit any incentive construction to maximize their private positive aspects while forsaking the original intent of the incentives.
Local Deepseek Online chat online is attention-grabbing in that the different variations have different bases. Elixir/Phoenix might do it also, though that forces an online app for an area API; didn’t seem practical. Tencent’s app integrates its in-house Hunyuan artificial intelligence tech alongside DeepSeek’s R1 reasoning model and has taken over at a time of acute curiosity and competition around AI within the country. However, the scaling regulation described in earlier literature presents varying conclusions, which casts a dark cloud over scaling LLMs. However, if what DeepSeek has achieved is true, they may quickly lose their advantage. This improvement is primarily attributed to enhanced accuracy in STEM-associated questions, the place significant good points are achieved via massive-scale reinforcement studying. While current reasoning fashions have limitations, this can be a promising analysis course as a result of it has demonstrated that reinforcement learning (with out people) can produce models that study independently. This is rather like how humans discover ways to exploit any incentive construction to maximize their private positive aspects while forsaking the original intent of the incentives.
This is in distinction to supervised studying, which, in this analogy, could be just like the recruiter giving me specific feedback on what I did mistaken and how to improve. Despite US export restrictions on critical hardware, DeepSeek has developed aggressive AI programs just like the DeepSeek R1, which rival industry leaders similar to OpenAI, while providing an alternate method to AI innovation. Still, there is a strong social, economic, and authorized incentive to get this proper-and the technology business has gotten significantly better through the years at technical transitions of this variety. Although OpenAI didn't release its secret sauce for doing this, 5 months later, DeepSeek was capable of replicate this reasoning behavior and publish the technical details of its approach. In response to benchmarks, DeepSeek’s R1 not solely matches OpenAI o1’s high quality at 90% cheaper value, it is usually nearly twice as fast, though OpenAI’s o1 Pro still gives better responses.
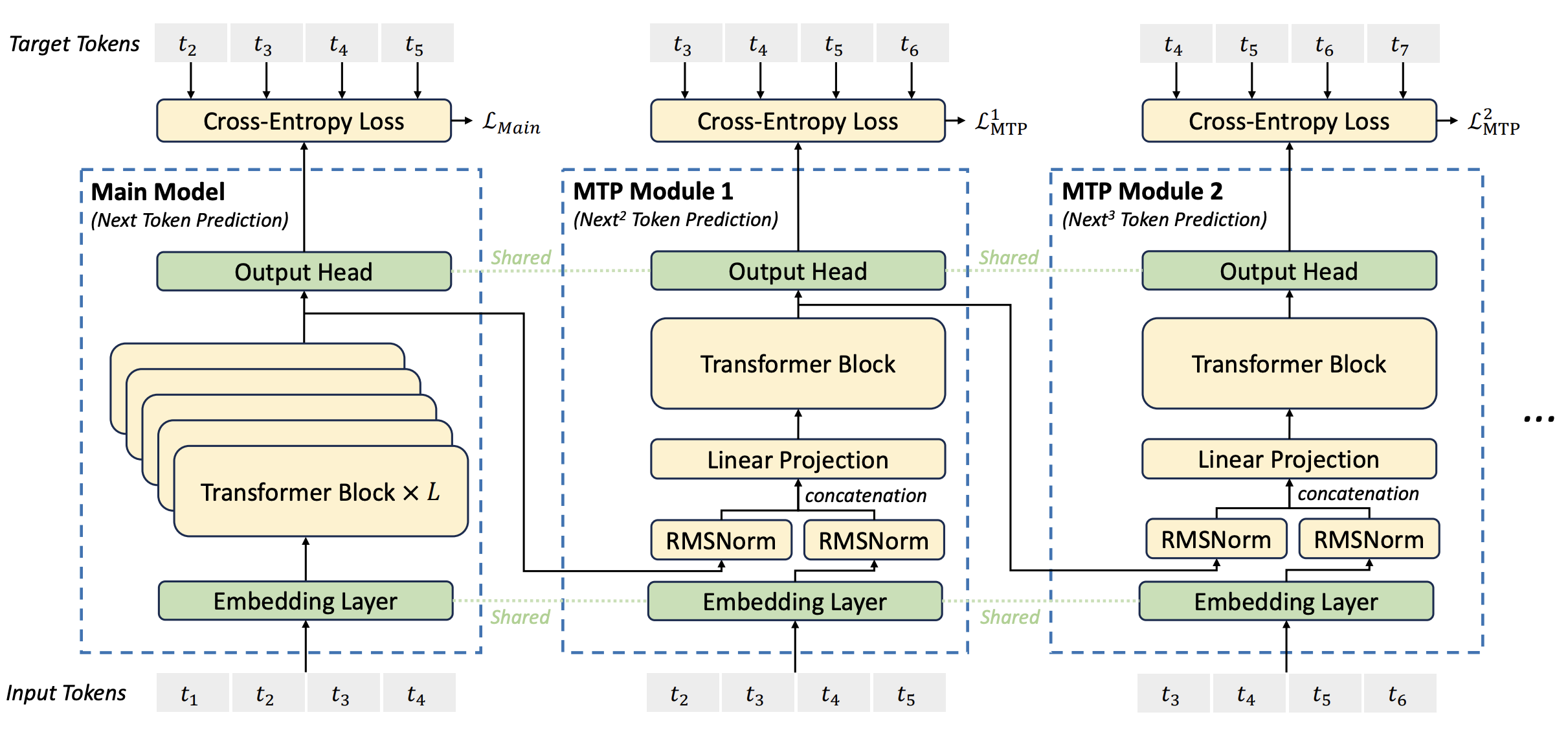
Within days of its release, the DeepSeek AI assistant -- a cellular app that gives a chatbot interface for DeepSeek-R1 -- hit the top of Apple's App Store chart, outranking OpenAI's ChatGPT mobile app. To be particular, we validate the MTP technique on top of two baseline models across totally different scales. • We examine a Multi-Token Prediction (MTP) goal and show it useful to model efficiency. At this point, the model probably has on par (or higher) performance than R1-Zero on reasoning duties. The 2 key advantages of this are, one, the desired response format might be explicitly proven to the mannequin, and two, seeing curated reasoning examples unlocks higher efficiency for the ultimate model. Notice the lengthy CoT and additional verification step before producing the final reply (I omitted some components because the response was very lengthy). Next, an RL coaching step is utilized to the model after SFT. To mitigate R1-Zero’s interpretability points, the authors explore a multi-step coaching strategy that makes use of each supervised effective-tuning (SFT) and RL. That’s why one other SFT round is carried out with both reasoning (600k examples) and non-reasoning (200k examples) knowledge.
If you cherished this information in addition to you would like to get guidance about deepseek français kindly pay a visit to our web site.
- 이전글Deepseek Ethics 25.03.22
- 다음글사랑의 산책: 애완동물과 함께 25.03.22
댓글목록
등록된 댓글이 없습니다.